Tag: BERT
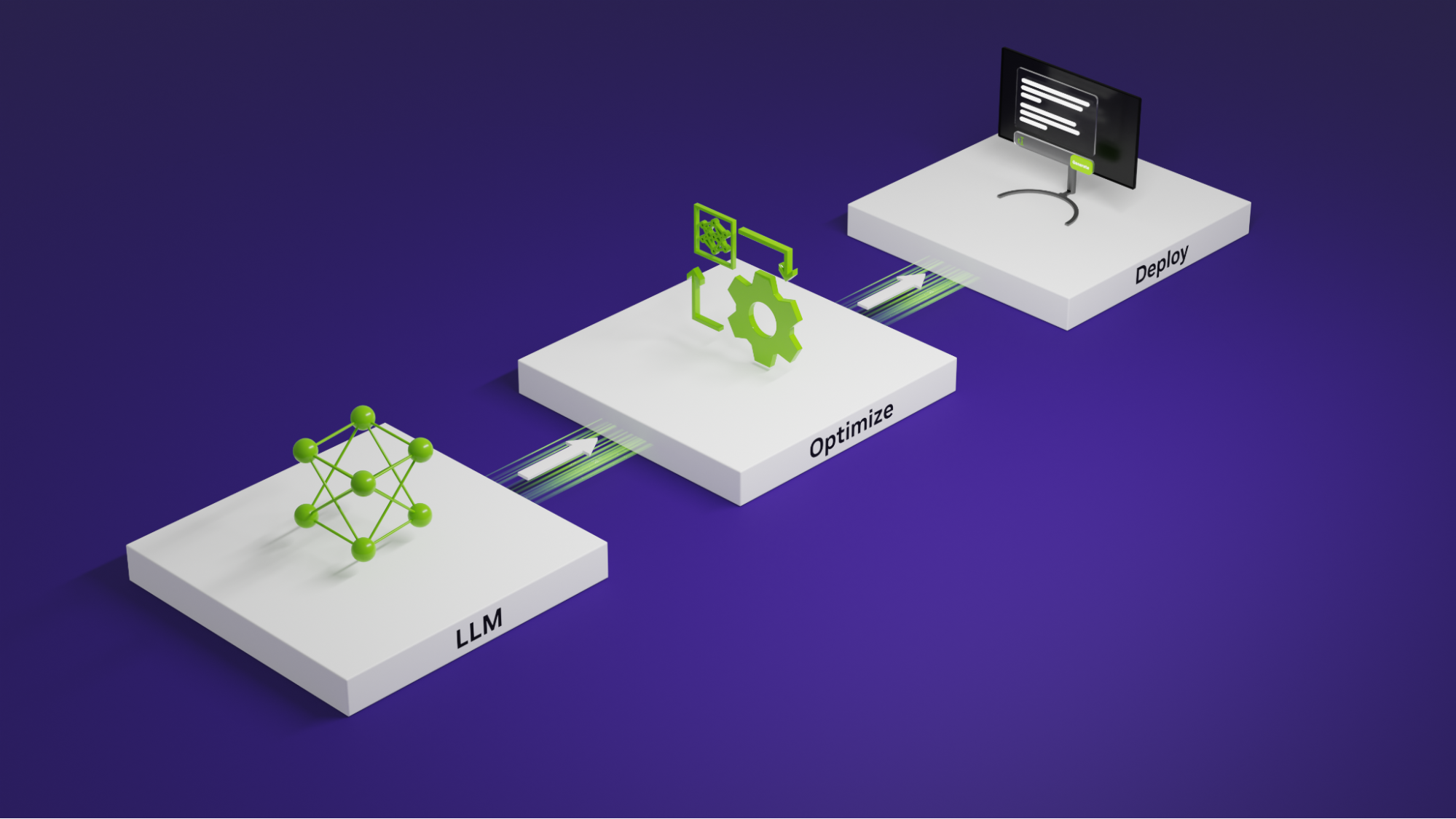
Mastering LLM Techniques: Inference Optimization | NVIDIA Technical Blog
0
July 2, 2024
0
Transformer models: an introduction and catalog — 2022 Edition
0
September 29, 2022
0

HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units
1
July 1, 2022
0

Deep Learning over the Internet: Training Language Models Collaboratively
0
October 18, 2021
0
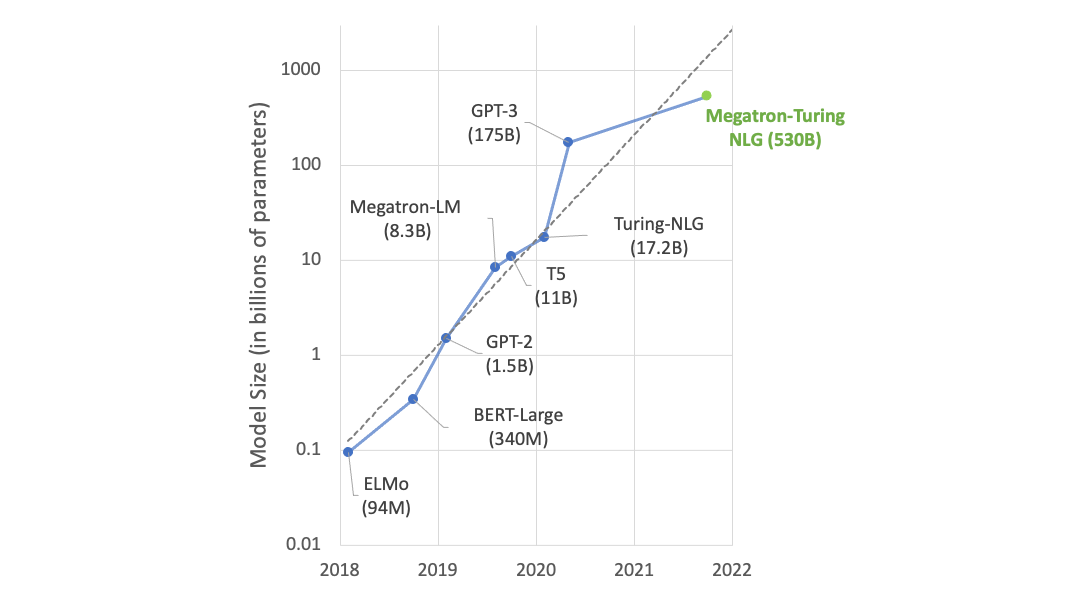
Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, the World’s Largest and Most Powerful Generative Language Model
0
October 15, 2021
0

The Definitive Guide to Embeddings
0
September 20, 2021
0
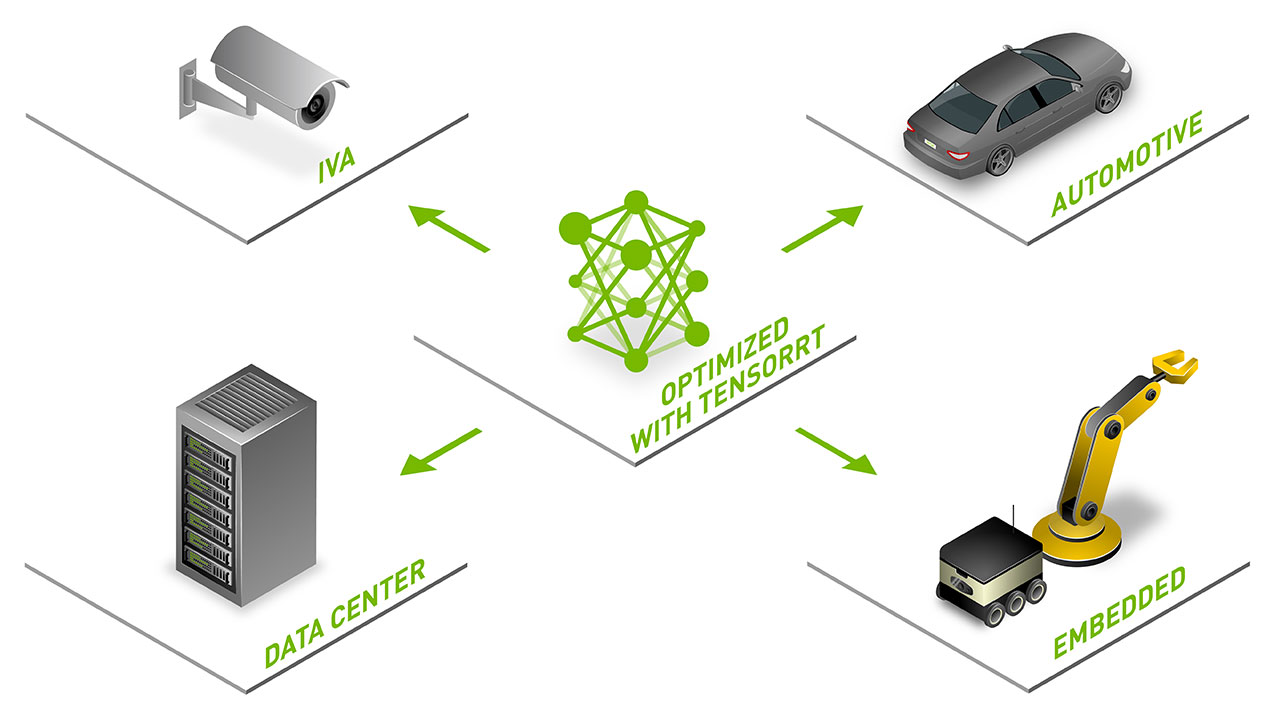
NVIDIA Announces TensorRT 8 Slashing BERT-Large Inference Down to 1 Millisecond
0
July 30, 2021
0

Google Replaces BERT Self-Attention with Fourier Transform: 92% Accuracy, 7 Times Faster on GPUs
0
June 16, 2021
0
A Deep Dive Into Machine Translation
0
April 15, 2021
0
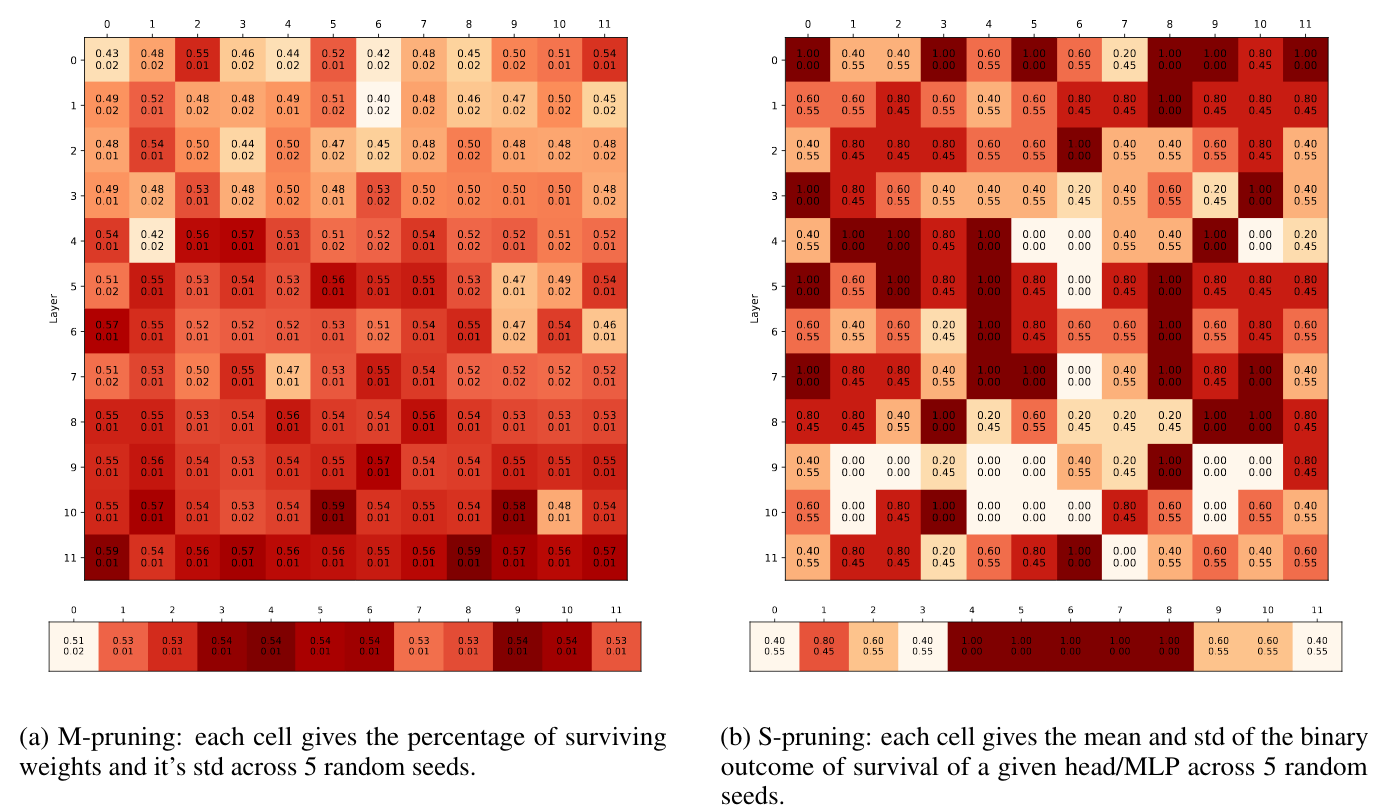
When BERT Plays The Lottery, All Tickets Are Winning
0
February 24, 2021
0
Training BERT at a University
0
December 28, 2020
0
Shrinking massive neural networks used to model language
0
December 10, 2020
0
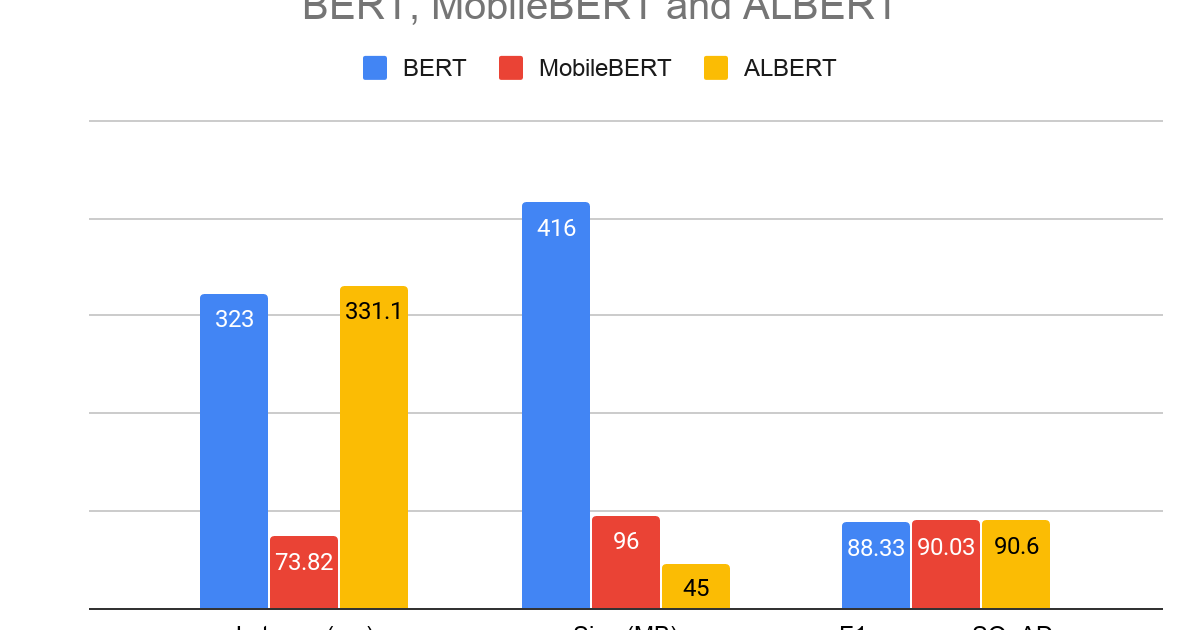
What’s new in TensorFlow Lite for NLP
0
September 28, 2020
0

Domain-specific language model pretraining for biomedical natural language processing – Microsoft Research
0
September 7, 2020
0

TaBERT: A new model for understanding queries over tabular data
0
September 4, 2020
0

How Smart is BERT? Evaluating the Language Model’s Commonsense Knowledge
0
August 17, 2020
0
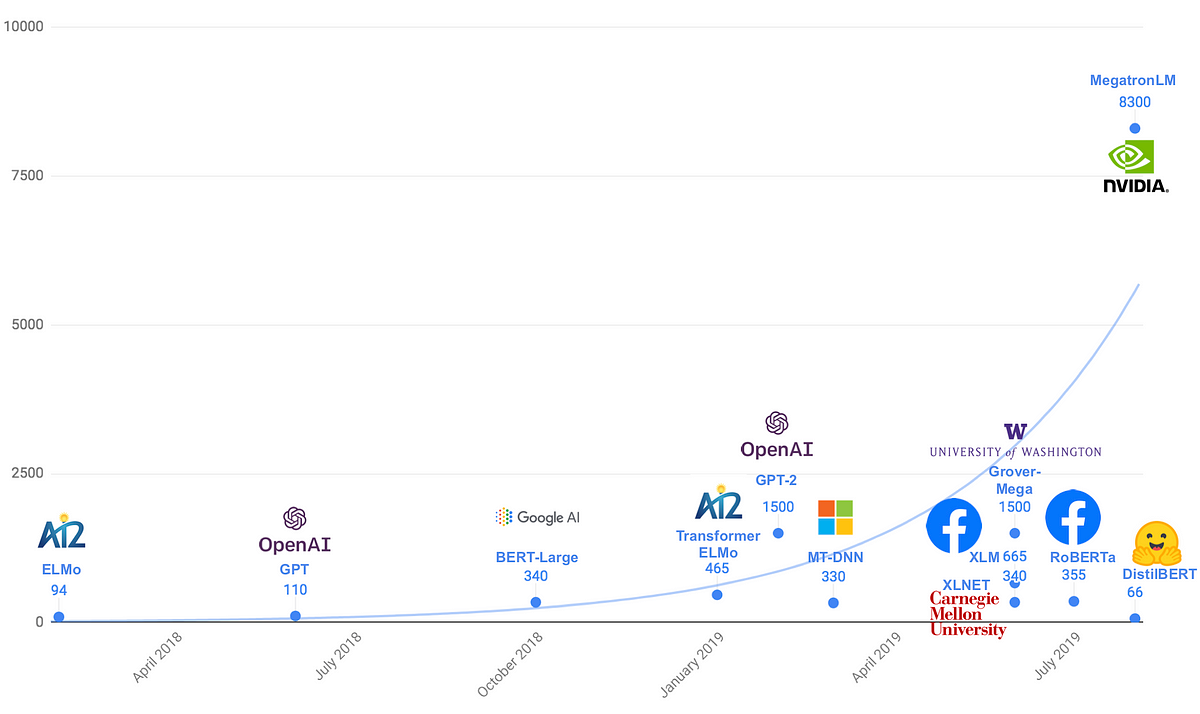
Smaller, faster, cheaper, lighter: Introducing DilBERT, a distilled version of BERT
0
March 21, 2020
0
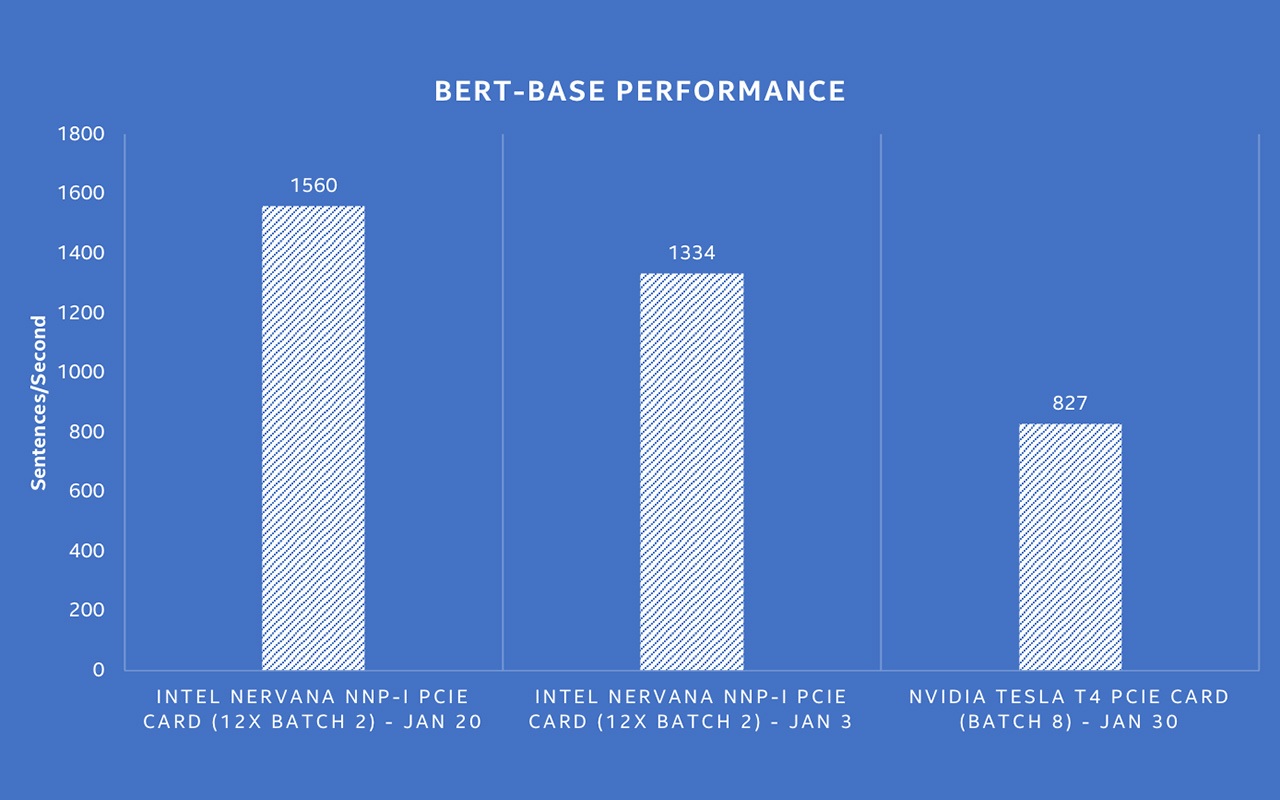
Intel® Nervana™ NNP-I Shows Best-in-Class Throughput on BERT NLP Model – Intel AI
0
February 5, 2020
0
ALBERT: A Lite BERT for Self-Supervised Learning of Language Representations
0
January 11, 2020
0
What does a Fine-tuned BERT model look at ?.
0
January 2, 2020
0

Understanding searches better than ever before
0
October 28, 2019
0
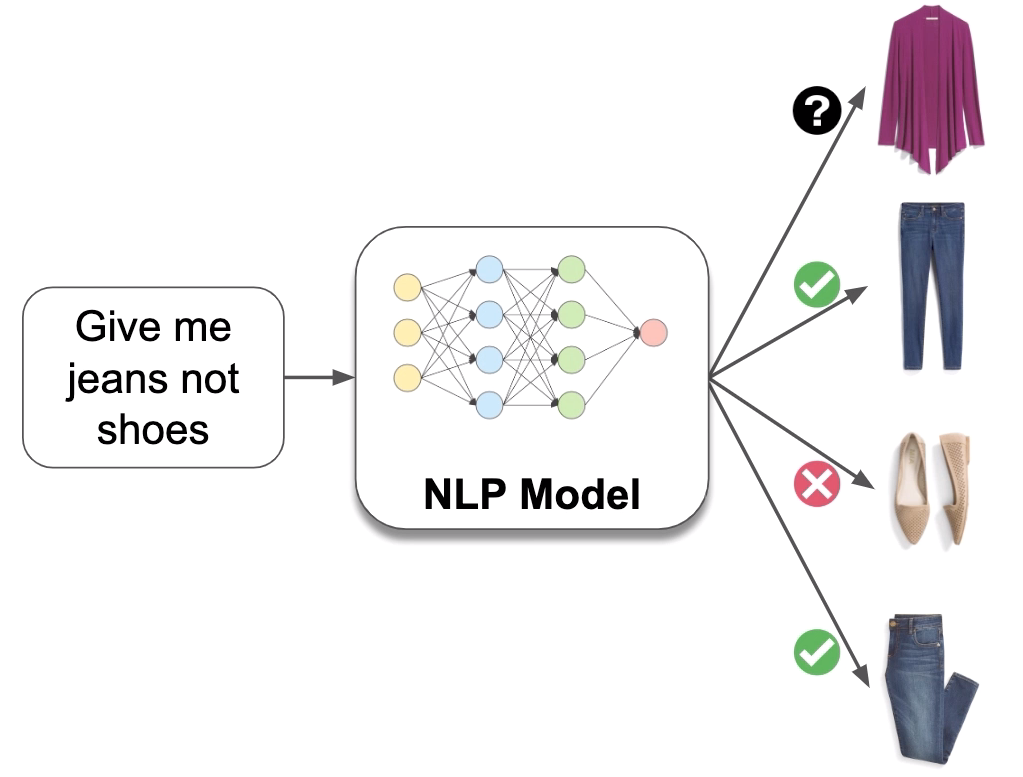
Give Me Jeans not Shoes: How BERT Helps Us Deliver What Clients Want | Stitch Fix Technology – Multithreaded
0
October 24, 2019
0
Learning Cross-Modal Temporal Representations from Unlabeled Videos
0
September 12, 2019
0

Habana Labs Goya Delivers Inferencing on BERT – Habana
0
August 16, 2019
0