Universal Speech Model (USM): State-of-the-art speech AI for 100+ languages
Universal Speech Model (USM): State-of-the-art speech AI for 100+ languages
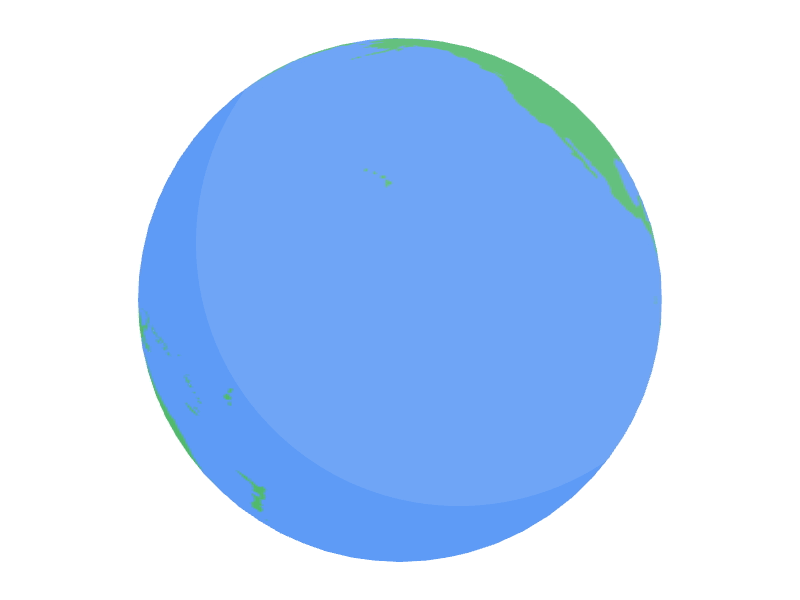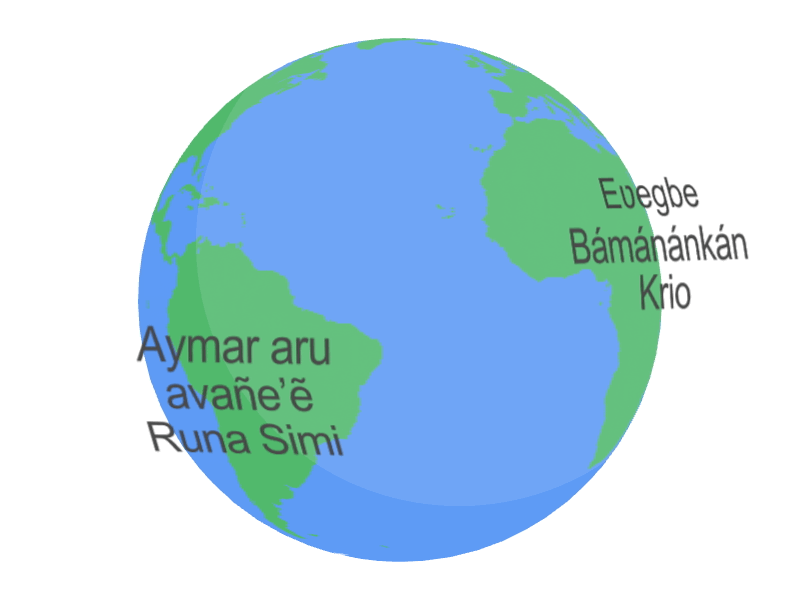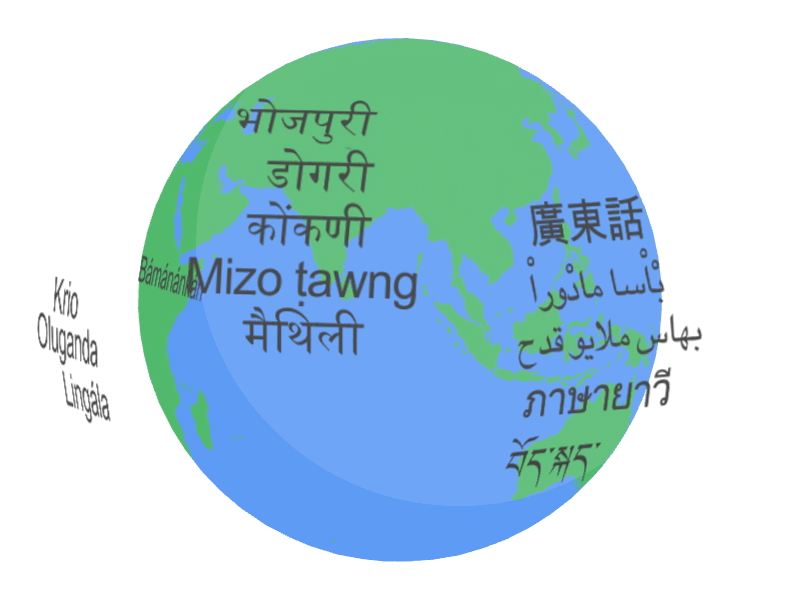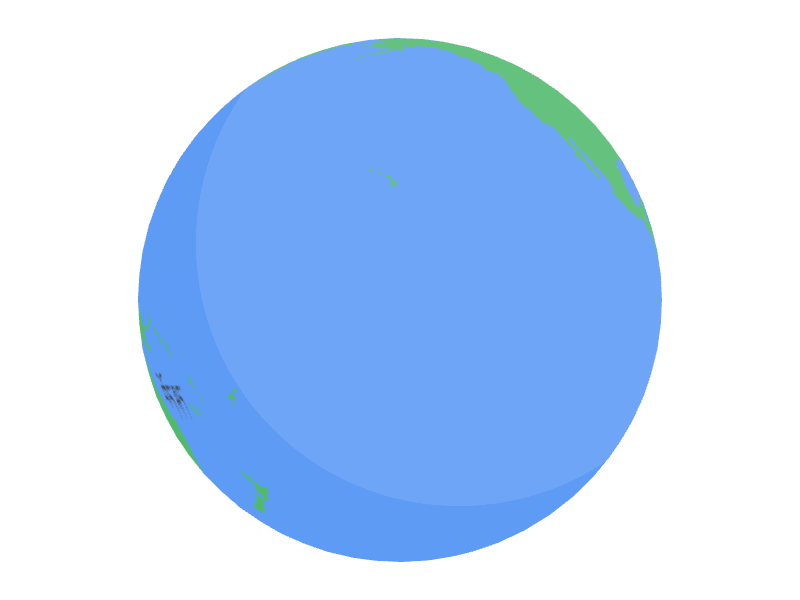
The article “Universal Speech Model (USM): The State of the Art” published on the Google AI blog provides an in-depth overview of the Universal Speech Model (USM), a new approach to speech recognition that achieves state-of-the-art performance on a wide range of speech recognition tasks.
The article begins by explaining the limitations of traditional speech recognition systems and how USM addresses these limitations. It then goes on to describe the architecture of USM, which is based on a neural network that uses a sequence-to-sequence model and a self-attention mechanism to capture contextual information in the input speech.
The authors of the article provide detailed results of their experiments, which demonstrate that USM outperforms other state-of-the-art models on a variety of speech recognition tasks, including those in low-resource languages and noisy environments. The article also highlights the potential applications of USM, such as in speech-to-speech translation, voice assistants, and transcription.
Overall, the article provides a clear and detailed explanation of the USM model and its performance, and highlights its potential impact on the field of speech recognition. It is a valuable read for anyone interested in the latest advancements in this field.