How Quantization Aware Training Enables Low-Precision Accuracy Recovery
How Quantization Aware Training Enables Low-Precision Accuracy Recovery | NVIDIA Technical Blog
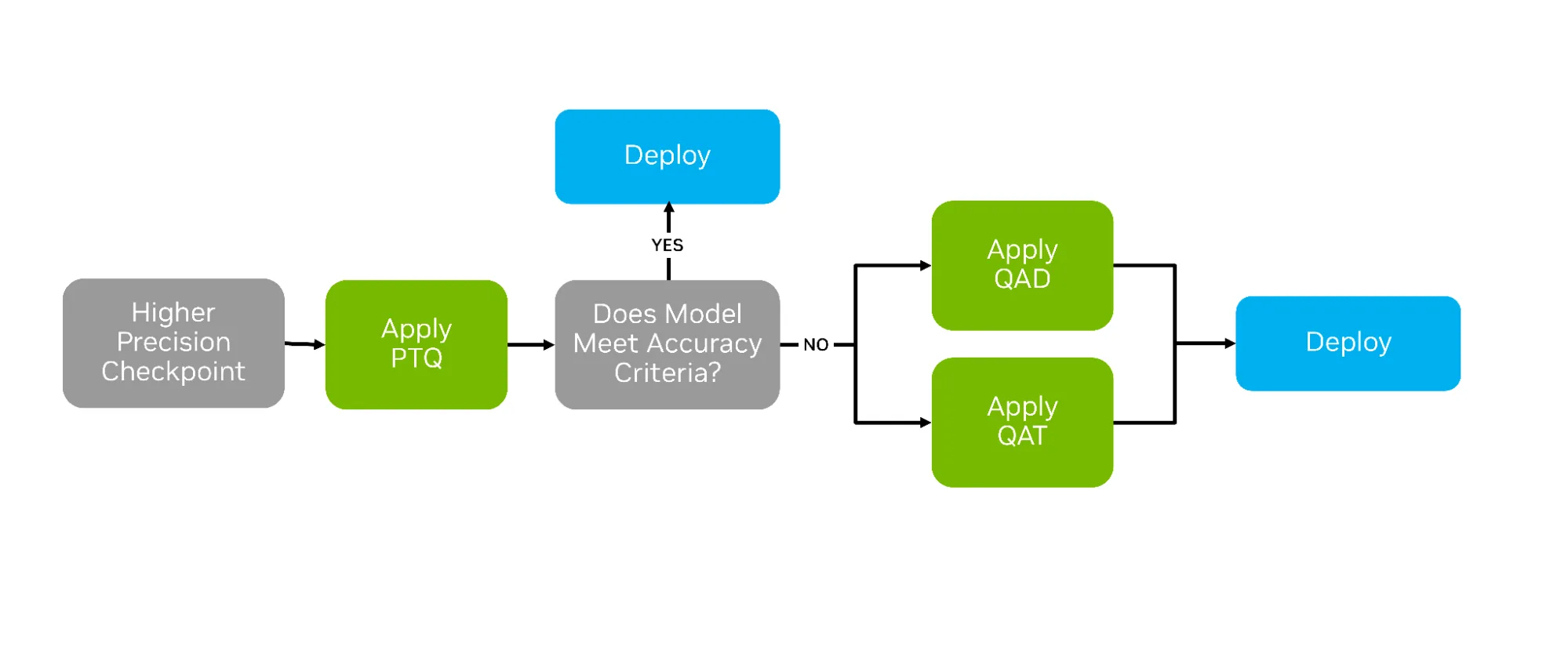
“After training AI models, a variety of compression techniques can be used to optimize them for deployment. The most common is post-training quantization (PTQ), which applies numerical scaling techniques to approximate model weights in lower-precision data types. But two other strategies—quantization aware training (QAT) and quantization aware distillation (QAD)—can succeed where PTQ falls short by actively preparing the model for life in lower precision (See Figure 1 below).
QAT and QAD aim to simulate the impact of quantization during post-training, allowing higher-precision model weights and activations to adapt to the new format’s representable range. This adaptation provides a smoother transition from higher to lower precisions, often yielding greater accuracy recovery…”
Source: developer.nvidia.com/blog/how-quantization-aware-training-enables-low-precision-accuracy-recovery