VDTTS: Visually-Driven Text-To-Speech
VDTTS: Visually-Driven Text-To-Speech
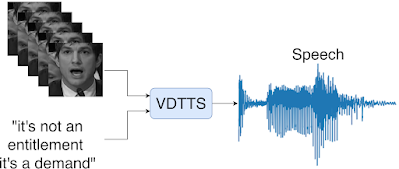
“Recent years have seen a tremendous increase in the creation and serving of video content to users across the world in a variety of languages and over numerous platforms. The process of creating high quality content can include several stages from video capturing and captioning to video and audio editing. In some cases dialogue is re-recorded (referred to as dialog replacement, post-sync or dubbing) in a studio in order to achieve high quality and replace original audio that might have been recorded in noisy conditions. However, the dialog replacement process can be difficult and tedious because the newly recorded audio needs to be well synced with the video, requiring several edits to match the exact timing of mouth movements…”
Source: ai.googleblog.com/2022/04/vdtts-visually-driven-text-to-speech.html