Sparsity in INT8: Training Workflow and Best Practices for NVIDIA TensorRT Acceleration
Sparsity in INT8: Training Workflow and Best Practices for NVIDIA TensorRT Acceleration | NVIDIA Technical Blog
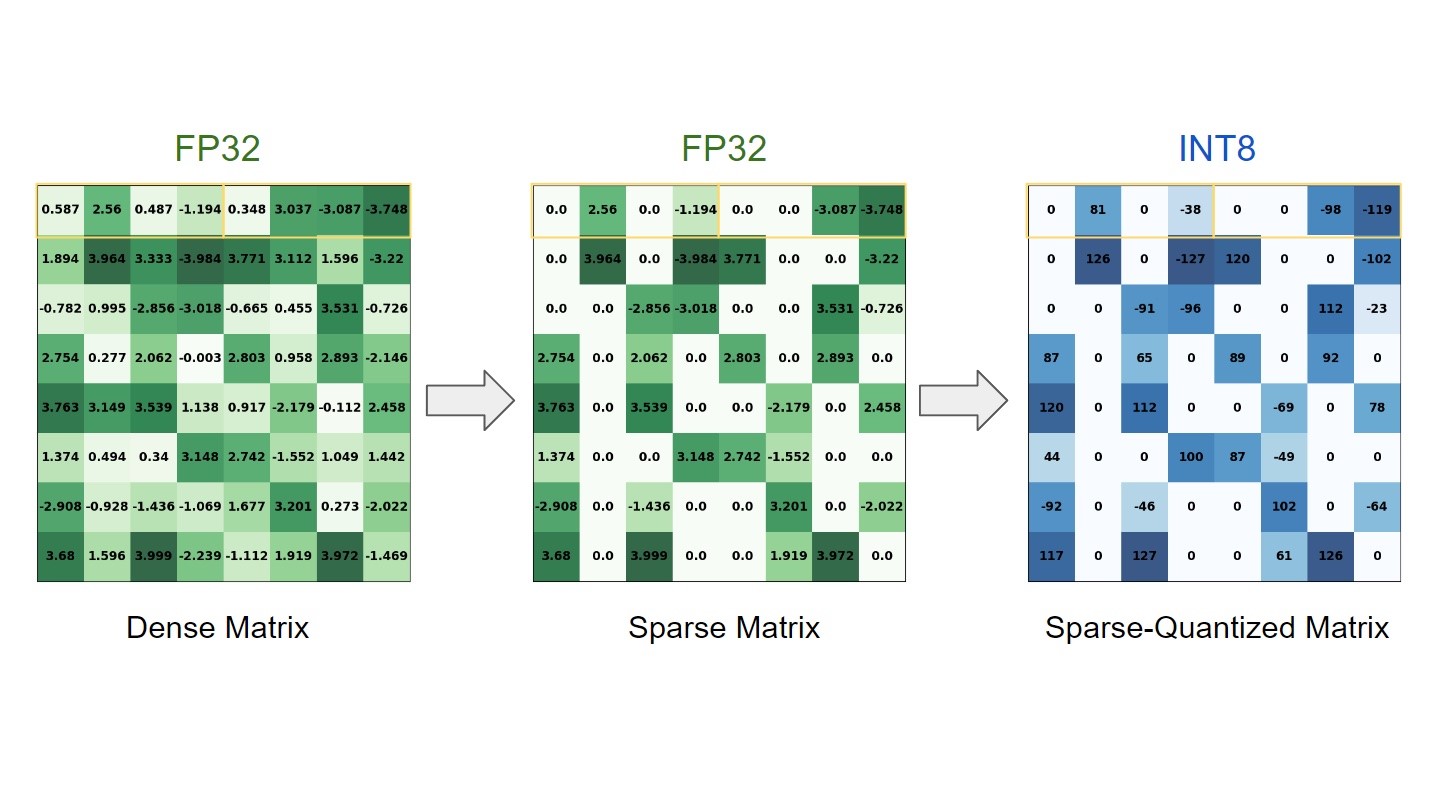
“The training stage of deep learning (DL) models consists of learning numerous dense floating-point weight matrices, which results in a massive amount of floating-point computations during inference. Research has shown that many of those computations can be skipped by forcing some weights to be zero, with little impact on the final accuracy.
In parallel to that, previous posts have shown that lower precision, such as INT8, is often sufficient to obtain similar accuracies to FP32 during inference. Sparsity and quantization are popular optimization techniques used to tackle these points, improving inference time and reducing memory footprint…”
June 3, 2023
Subscribe
Login
Please login to comment
0 Comments