End-to-End AI for NVIDIA-Based PCs: CUDA and TensorRT Execution Providers in ONNX Runtime
End-to-End AI for NVIDIA-Based PCs: CUDA and TensorRT Execution Providers in ONNX Runtime | NVIDIA Technical Blog
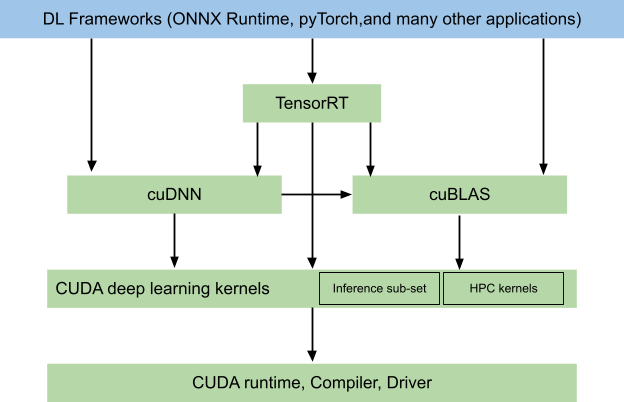
“The CUDA EP uses the cuDNN inference library, which is based on granular operation blocks for neural networks. Such building blocks could resemble a convolution, or a fused operator; for example, a convolution+activation+normalization.
The benefit of having fused operators is to have less global memory traffic that typically is a bottleneck on inexpensive operations like an activation function. Such operation blocks can either be selected by an exhaustive search or heuristics that picks a kernel depending on the GPU.
The exhaustive search is only done during the first inference on the deployed device, therefore making the first inference slower than the following ones. This leads to always using the most performant implementation for a specific block…”