AudioLM: a Language Modeling Approach to Audio Generation
AudioLM: a Language Modeling Approach to Audio Generation
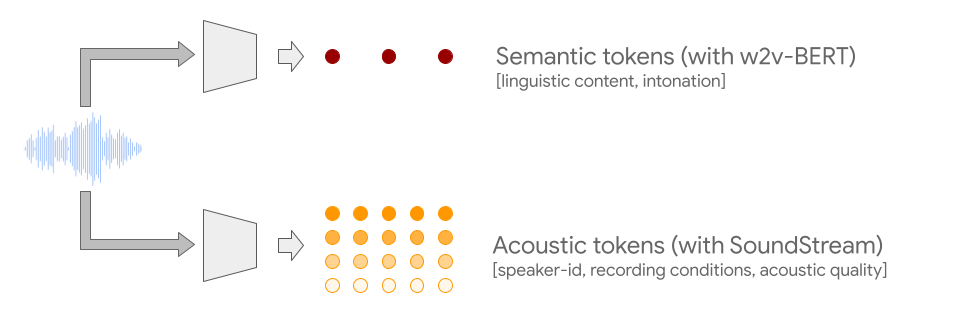
“Generating realistic audio requires modeling information represented at different scales. For example, just as music builds complex musical phrases from individual notes, speech combines temporally local structures, such as phonemes or syllables, into words and sentences. Creating well-structured and coherent audio sequences at all these scales is a challenge that has been addressed by coupling audio with transcriptions that can guide the generative process, be it text transcripts for speech synthesis or MIDI representations for piano. However, this approach breaks when trying to model untranscribed aspects of audio, such as speaker characteristics necessary to help people with speech impairments recover their voice, or stylistic components of a piano performance.
In “AudioLM: a Language Modeling Approach to Audio Generation”, we propose a new framework for audio generation that learns to generate realistic speech and piano music by listening to audio only. Audio generated by AudioLM demonstrates long-term consistency (e.g., syntax in speech, melody in music) and high fidelity, outperforming previous systems and pushing the frontiers of audio generation with applications in speech synthesis or computer-assisted music. Following our AI Principles, we’ve also developed a model to identify synthetic audio generated by AudioLM…”
Source: ai.googleblog.com/2022/10/audiolm-language-modeling-approach-to.html