Transformers for Image Recognition at Scale
Transformers for Image Recognition at Scale
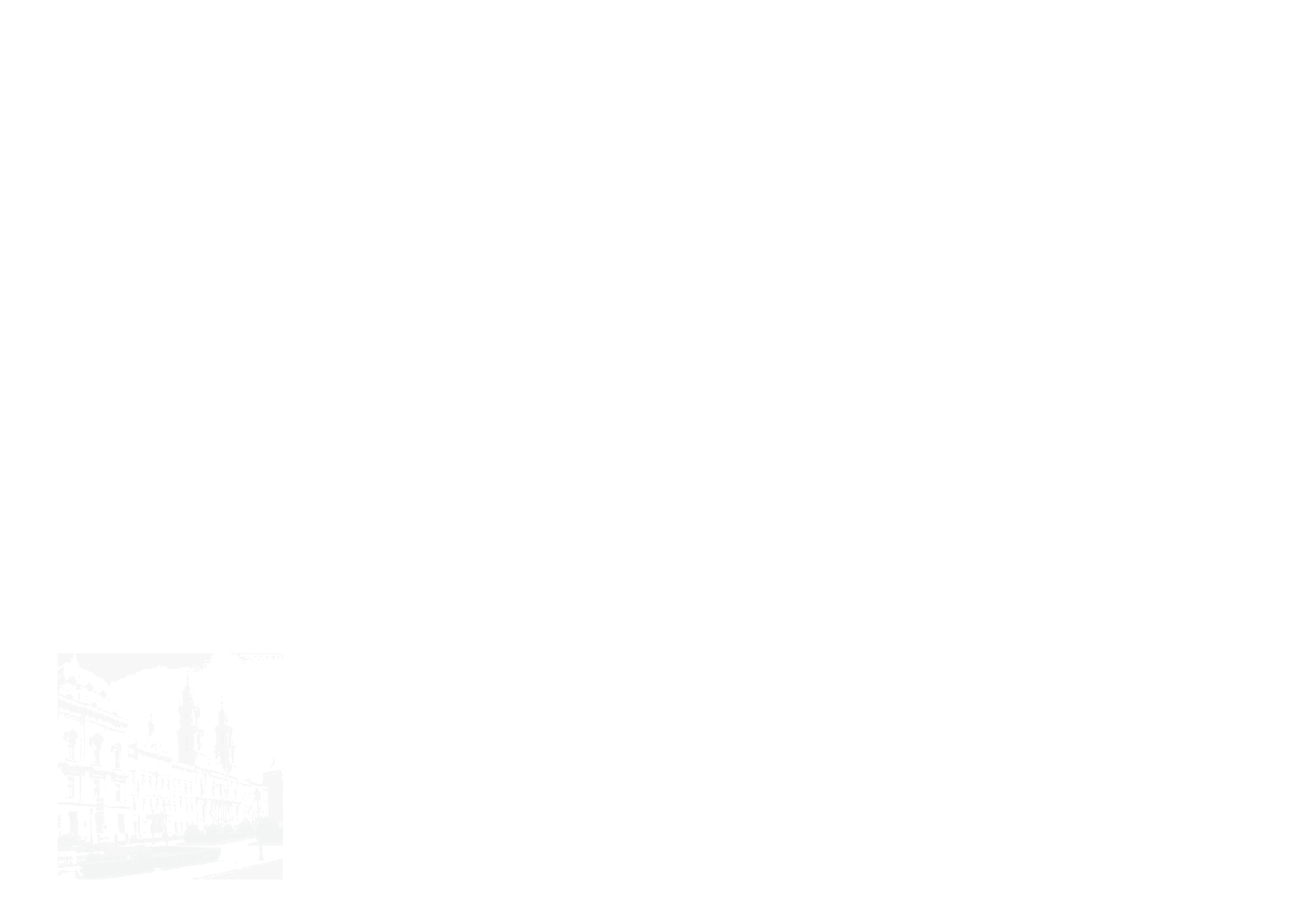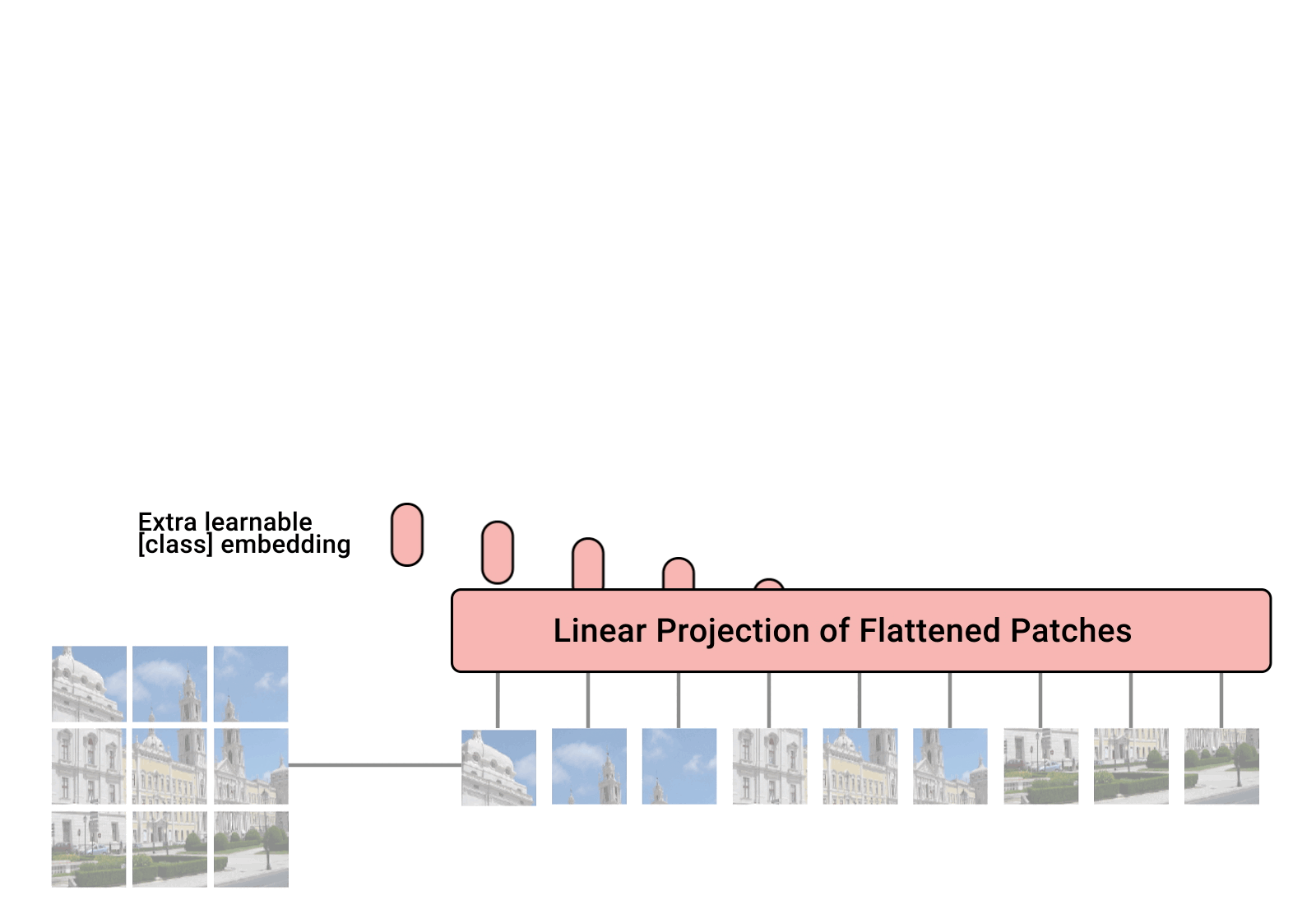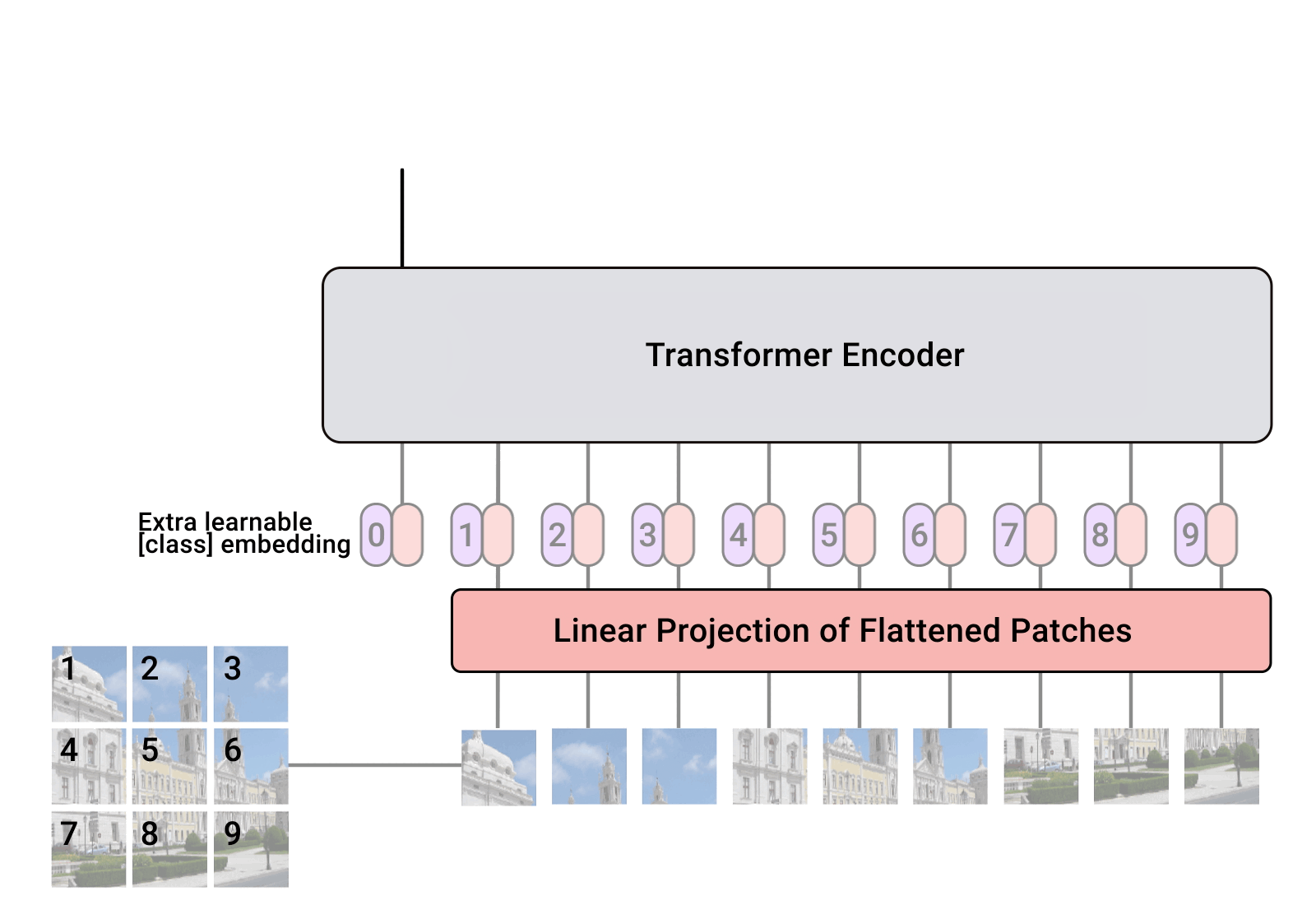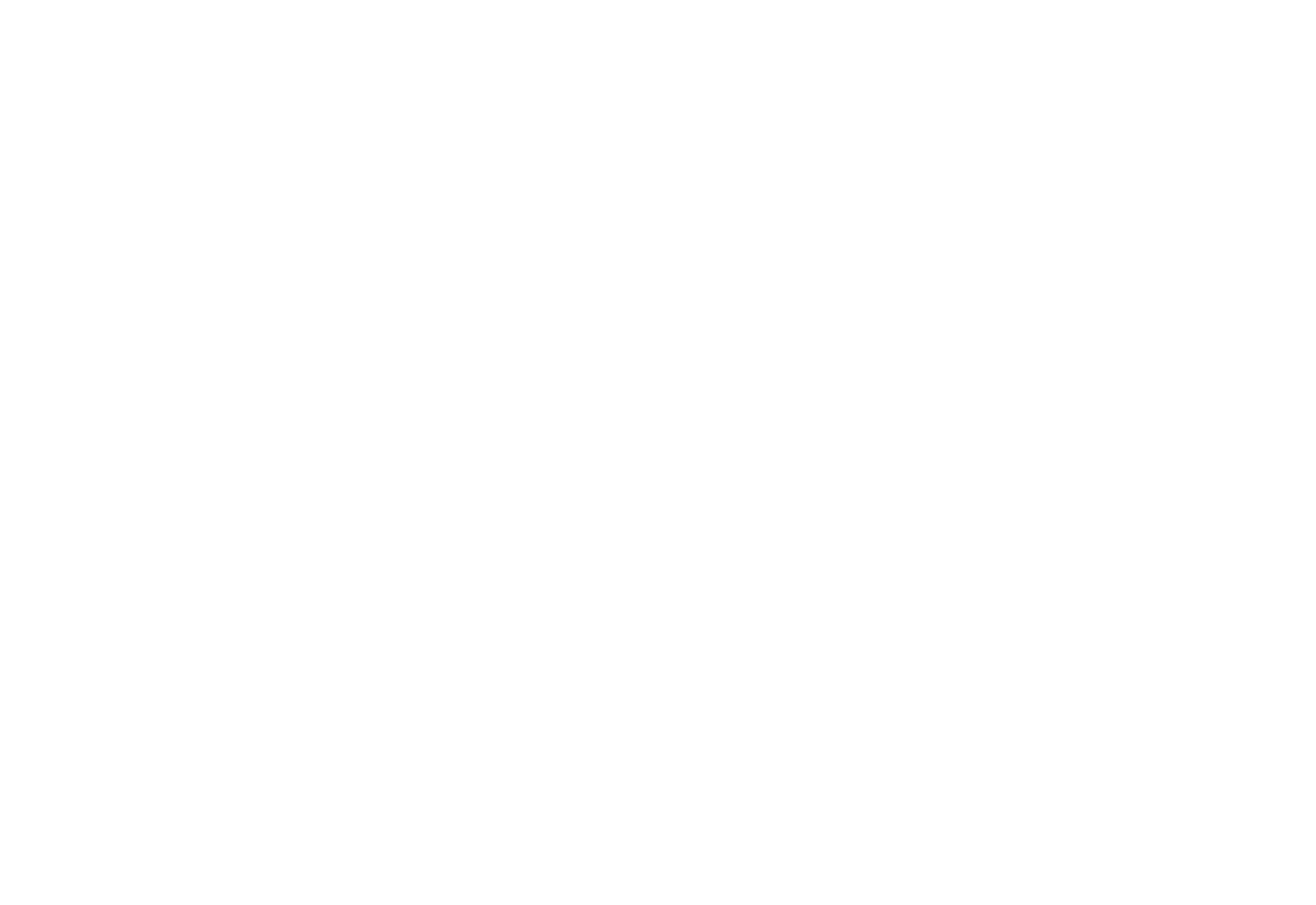
“While convolutional neural networks (CNNs) have been used in computer vision since the 1980s, they were not at the forefront until 2012 when AlexNet surpassed the performance of contemporary state-of-the-art image recognition methods by a large margin. Two factors helped enable this breakthrough: (i) the availability of training sets like ImageNet, and (ii) the use of commoditized GPU hardware, which provided significantly more compute for training. As such, since 2012, CNNs have become the go-to model for vision tasks.
The benefit of using CNNs was that they avoided the need for hand-designed visual features, instead learning to perform tasks directly from data “end to end”. However, while CNNs avoid hand-crafted feature-extraction, the architecture itself is designed specifically for images and can be computationally demanding. Looking forward to the next generation of scalable vision models, one might ask whether this domain-specific design is necessary, or if one could successfully leverage more domain agnostic and computationally efficient architectures to achieve state-of-the-art results…”
Source: ai.googleblog.com/2020/12/transformers-for-image-recognition-at.html