Rethinking Attention with Performers
Rethinking Attention with Performers
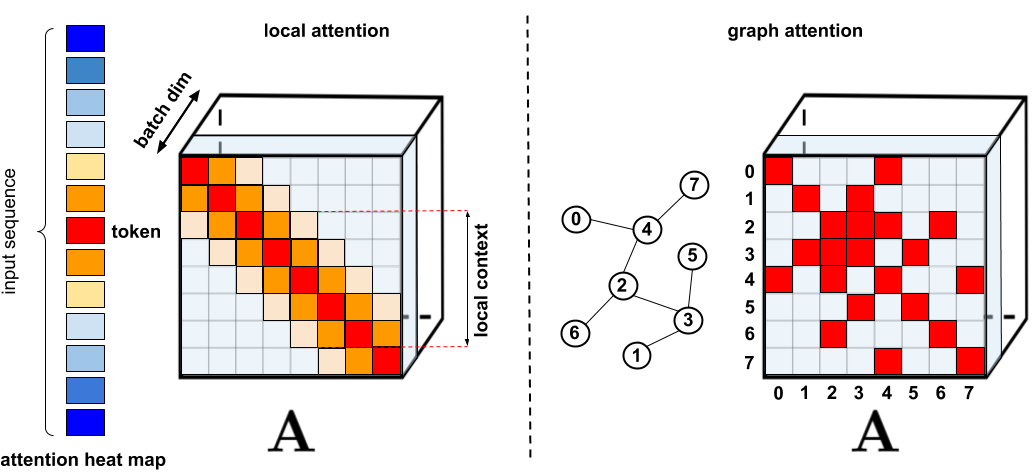
“Transformer models have achieved state-of-the-art results across a diverse range of domains, including natural language, conversation, images, and even music. The core block of every Transformer architecture is the attention module, which computes similarity scores for all pairs of positions in an input sequence. This however, scales poorly with the length of the input sequence, requiring quadratic computation time to produce all similarity scores, as well as quadratic memory size to construct a matrix to store these scores….”
Source: ai.googleblog.com/2020/10/rethinking-attention-with-performers.html
December 23, 2020
Subscribe
Login
Please login to comment
0 Comments