PyTorch
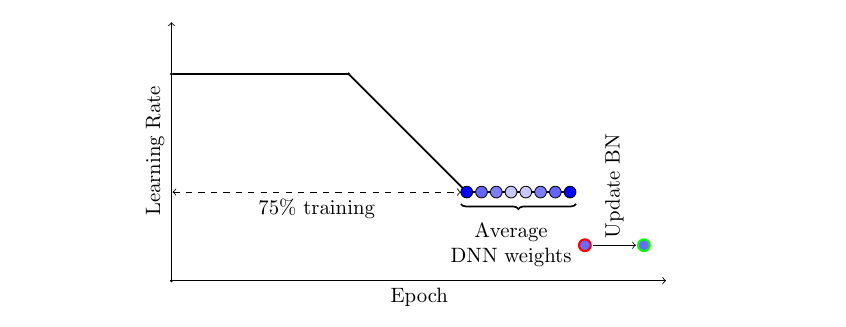
Do you use stochastic gradient descent (SGD) or Adam? Regardless of the procedure you use to train your neural network, you can likely achieve significantly better generalization at virtually no additional cost with a simple new technique now natively supported in PyTorch 1.6, Stochastic Weight Averaging (SWA). Even if you have already trained your model, it’s easy to realize the benefits of SWA by running SWA for a small number of epochs starting with a pre-trained model…
Source: pytorch.org/blog/pytorch-1.6-now-includes-stochastic-weight-averaging/
September 8, 2020
Subscribe
Login
Please login to comment
0 Comments