Positive and Unlabeled Learning (PUL) Using PyTorch
Positive and Unlabeled Learning (PUL) Using PyTorch — Visual Studio Magazine
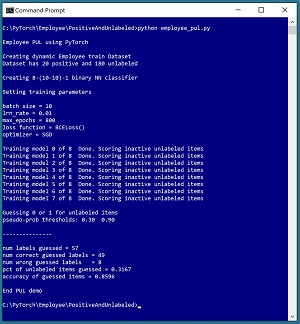
“A positive and unlabeled learning (PUL) problem occurs when a machine learning set of training data has only a few positive labeled items and many unlabeled items. PUL problems often occur with security or medical data. For example, suppose you want to train a machine learning model to predict if a hospital patient has a disease or not, based on predictor variables such as age, blood pressure, and so on. The training data might have a few dozen instances of items that are positive (class 1 = patient has disease) and many hundreds or thousands of instances of data items that are unlabeled and so could be either class 1 = patient has disease, or class 0 = patient does not have disease.
The goal of PUL is to use the information contained in the dataset to guess the true labels of the unlabeled data items. After the class labels of some of the unlabeled items have been guessed, the resulting labeled dataset can be used to train a binary classification model using any standard machine learning technique, such as k-nearest neighbors classification, neural binary classification, logistic regression classification, naive Bayes classification, and so on…”
Source: visualstudiomagazine.com/articles/2021/05/20/pul-pytorch.aspx