How Transformers work in deep learning and NLP: an intuitive introduction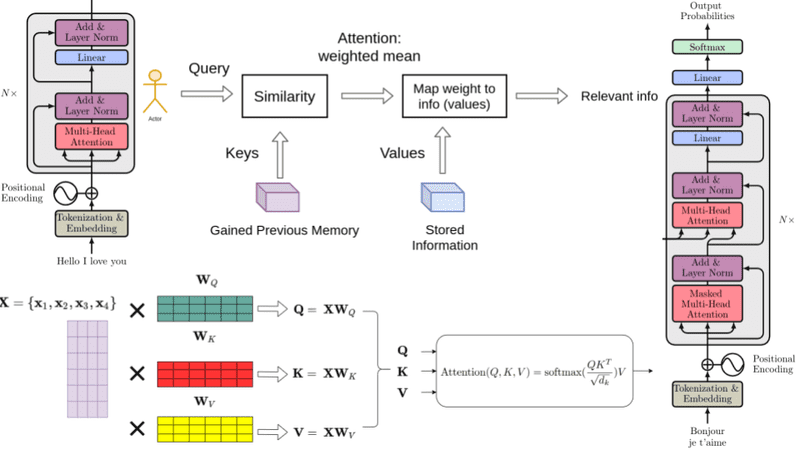
“The famous paper “Attention is all you need” in 2017 changed the way we were thinking about attention. With enough data, matrix multiplications, linear layers, and layer normalization we can perform state-of-the-art-machine-translation.
Nonetheless, 2020 was definitely the year of transformers! From natural language now they are into computer vision tasks. How did we go from attention to self-attention? Why does the transformer work so damn well? What are the critical components for its success?
Read on and find out!
In my opinion, transformers are not so hard to grasp. It’s the combination of all the surrounding concepts that may be confusing, including attention. That’s why we will slowly build around all the fundamental concepts.
With Recurrent Neural Networks (RNN’s) we used to treat sequences sequentially to keep the order of the sentence in place. To satisfy that design, each RNN component (layer) needs the previous (hidden) output. As such, stacked LSTM computations were performed sequentially…”
Source: theaisummer.com/transformer/