Deploying GPT-J and T5 with FasterTransformer and Triton Inference Server
Deploying GPT-J and T5 with FasterTransformer and Triton Inference Server | NVIDIA Technical Blog
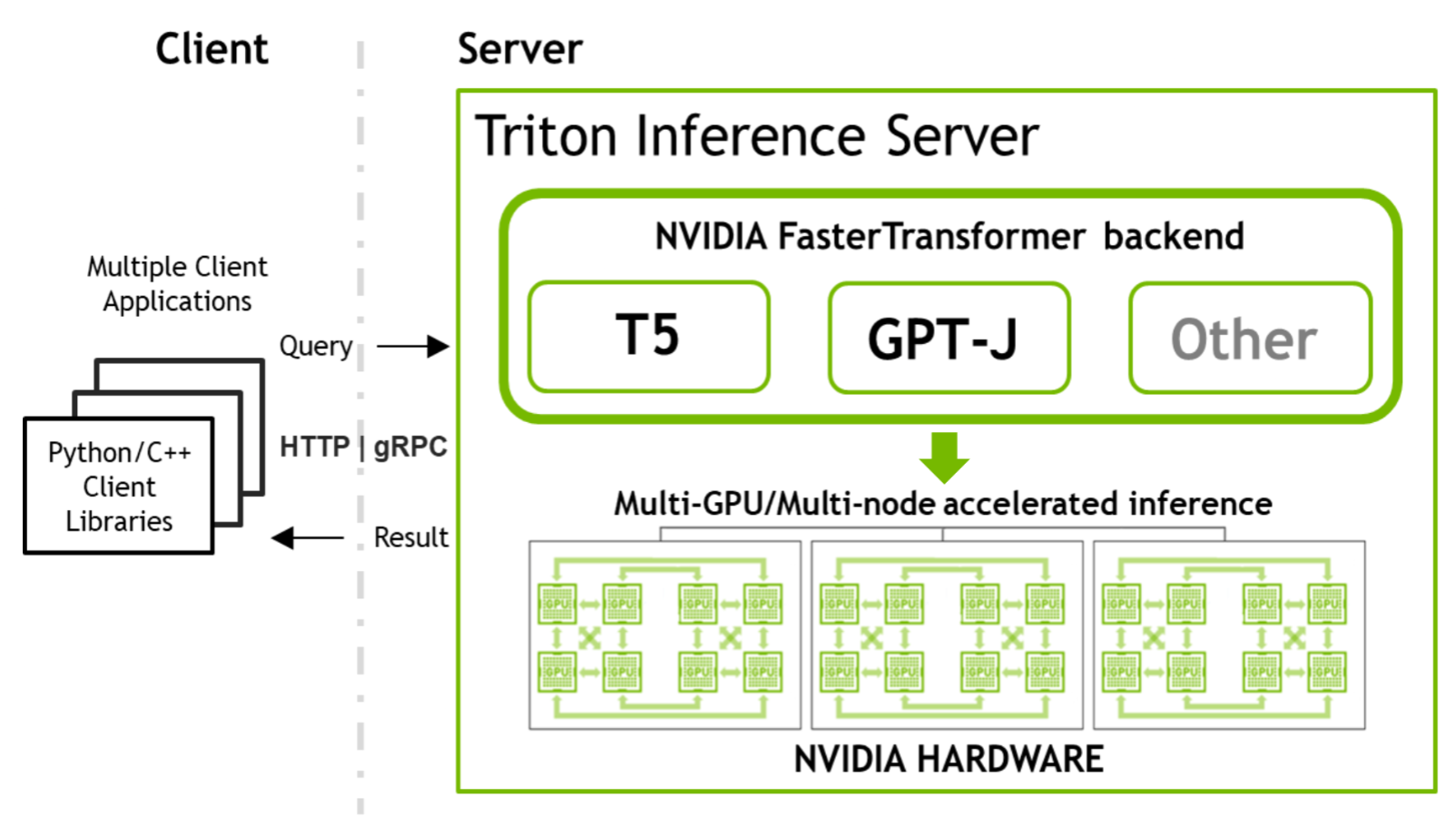
“NVIDIA FasterTransformer (FT) in NVIDIA Triton allows you to run both of these models in a similar and simple manner while providing enough flexibility to integrate/combine with other inference or training pipelines. The same NVIDIA software stack can be used for inference of the trillion-parameters models combining tensor parallelism (TP) and pipeline parallelism (PP) techniques on multiple nodes.
Transformer models are increasingly used in numerous domains and demonstrate outstanding accuracy. More importantly, the size of the model directly affects its quality. Apart from the NLP, this is applicable to other domains as well.
Researchers from Google demonstrated that the scaling of the transformer-based text encoder was crucial for the whole image generation pipeline in their Imagen model, the latest and one of the most promising generative text-to-image models. Scaling the transformers leads to outstanding results in both single and multi-domain pipelines. This guide uses transformer-based models of the same structure and a similar size…”
Source: developer.nvidia.com/blog/deploying-gpt-j-and-t5-with-fastertransformer-and-triton-inference-server/