3D Aware Region Prompted Vision Language Model
3D Aware Region Prompted Vision Language Model
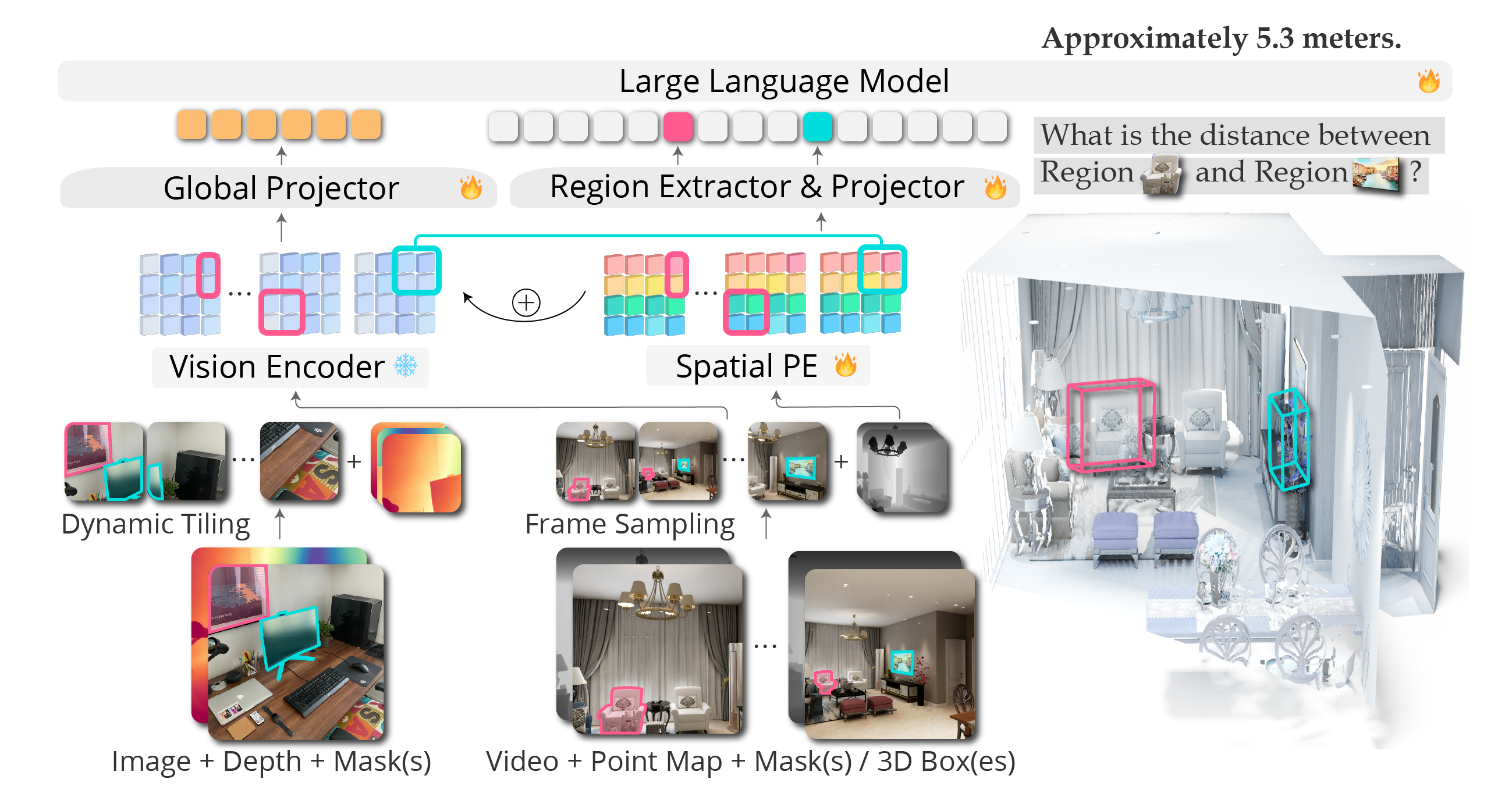
AI-generated review:
SR-3D introduces a novel vision-language model that excels in spatial reasoning without relying on sensory 3D inputs. It leverages a unified canonical positional representation across single-view and multi-view scenes, enabling effective pretraining and transfer of spatial priors. The model significantly outperforms NVILA-Lite-8B on 2D spatial benchmarks, demonstrating enhanced spatial understanding. SR-3D showcases impressive region-level reasoning, correctly answering queries even when region prompts are reused across samples. It maintains high accuracy on 3D scene benchmarks like VSI-Bench, even without explicit region prompts. The architecture smartly balances frozen and trainable parameters to optimize performance. Overall, SR-3D sets a new standard for 3D-aware spatial reasoning in vision-language models.
Source: www.anjiecheng.me/sr3d